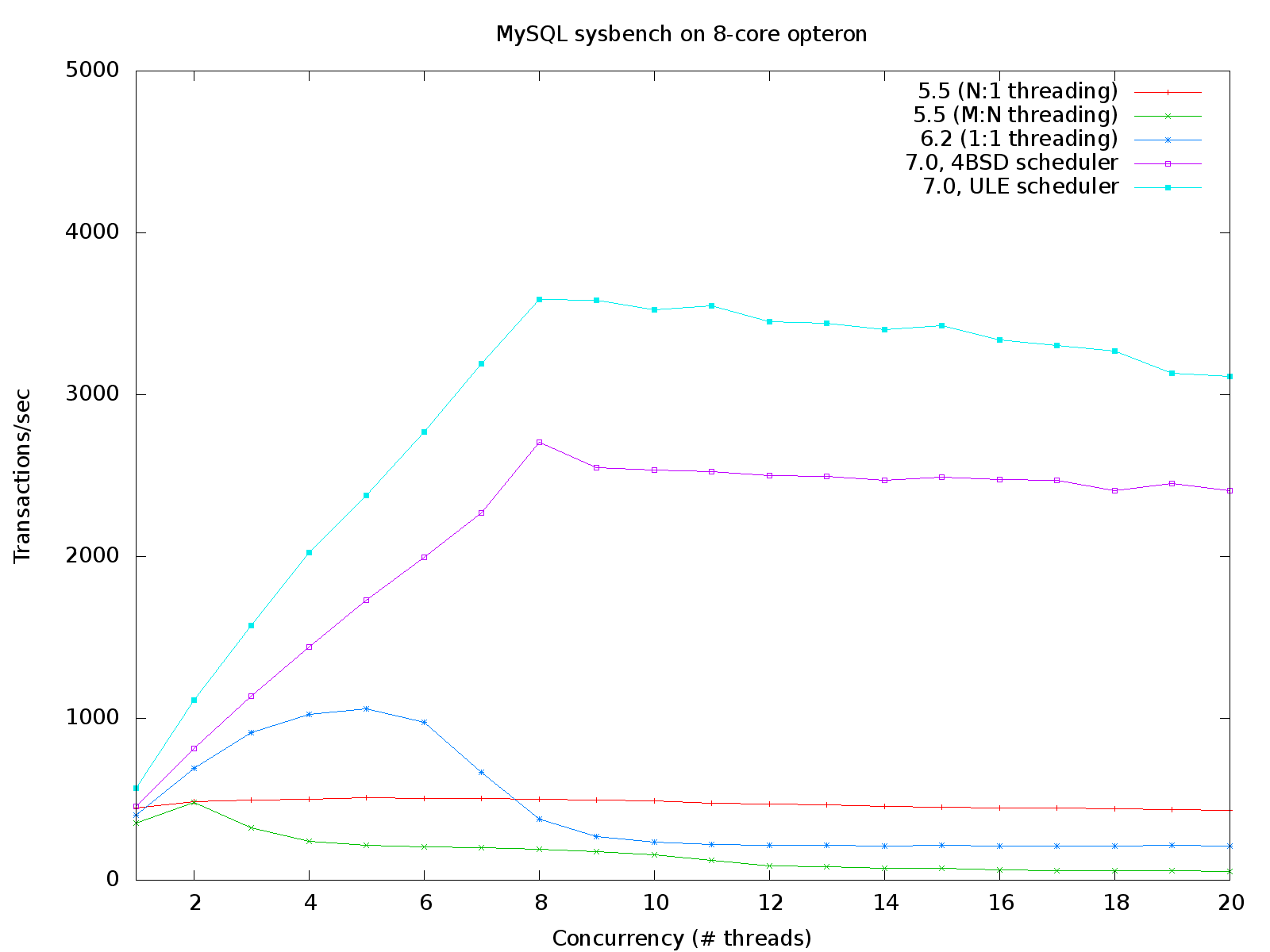
Post by O. HartmannPost by Volodymyr KostyrkoNot fully right, boinc defaults to run on idprio 31 so this isn't an
issue. And yes, there are cases where SCHED_ULE shows much better
performance then SCHED_4BSD. [...]
Do we have any proof at hand for such cases where SCHED_ULE performs
much better than SCHED_4BSD? Whenever the subject comes up, it is
mentioned, that SCHED_ULE has better performance on boxes with a ncpu >
2. But in the end I see here contradictionary statements. People
complain about poor performance (especially in scientific environments),
and other give contra not being the case.
Within our department, we developed a highly scalable code for planetary
science purposes on imagery. It utilizes present GPUs via OpenCL if
present. Otherwise it grabs as many cores as it can.
By the end of this year I'll get a new desktop box based on Intels new
Sandy Bridge-E architecture with plenty of memory. If the colleague who
developed the code is willing performing some benchmarks on the same
hardware platform, we'll benchmark bot FreeBSD 9.0/10.0 and the most
recent Suse. For FreeBSD I intent also to look for performance with both
different schedulers available.
This is in no way shape or form the same kind of benchmark as what
you're planning to do, but I thought I'd throw it out there for folks to
take in as they see fit.
I know folks were focused mainly on buildworld.
I personally would find it interesting if someone with a higher-end
system (e.g. 2 physical CPUs, with 6 or 8 cores per CPU) was to do the
same test (changing -jX to -j{numofcores} of course).
--
| Jeremy Chadwick jdc at parodius.com |
| Parodius Networking http://www.parodius.com/ |
| UNIX Systems Administrator Mountain View, CA, US |
| Making life hard for others since 1977. PGP 4BD6C0CB |
sched_ule
===========
- time make -j2 buildworld
1689.831u 229.328s 18:46.20 170.4% 6566+2051k 432+4264io 4565pf+0w
- time make -j2 buildkernel
640.542u 87.737s 9:01.38 134.5% 6490+1920k 134+5968io 0pf+0w
sched_4bsd
============
- time make -j2 buildworld
1662.793u 206.908s 17:12.02 181.1% 6578+2054k 23750+4271io 6451pf+0w
- time make -j2 buildkernel
638.717u 76.146s 8:34.90 138.8% 6530+1927k 6415+5903io 0pf+0w
software
==========
* sched_ule test: FreeBSD 8.2-STABLE, Thu Dec 1 04:37:29 PST 2011
* sched_4bsd test: FreeBSD 8.2-STABLE, Mon Dec 12 22:42:54 PST 2011
hardware
==========
* Intel Core 2 Duo E8400, 3GHz
* Supermicro X7SBA
* 8GB ECC RAM (4x2GB), DDR2-800
* Intel 320-series SSD, 80GB: /, swap, /var, /tmp, /usr
tuning adjustments / etc.
===========================
* Before each scheduler test, system was rebooted to ensure I/O cache
and other whatnots were empty
* All filesystems stock UFS2 + SU (root is non-SU)
* All filesystems had tunefs -t enable applied to them
* powerd(8) in use, with two rc.conf variables (per CPU spec):
performance_cx_lowest="C2"
economy_cx_lowest="C2"
* loader.conf
kern.maxdsiz="2560M"
kern.dfldsiz="2560M"
kern.maxssiz="256M"
ahci_load="yes"
hint.p4tcc.0.disabled="1"
hint.acpi_throttle.0.disabled="1"
vfs.zfs.arc_max="5120M"
* make.conf
CPUTYPE?=core2
* src.conf
WITHOUT_INET6=true
WITHOUT_IPFILTER=true
WITHOUT_LIB32=true
WITHOUT_KERBEROS=true
WITHOUT_PAM_SUPPORT=true
WITHOUT_PROFILE=true
WITHOUT_SENDMAIL=true
* kernel configuration
- note: between kernel builds, config was changed to either use
SCHED_4BSD or SCHED_ULE respectively.
cpu HAMMER
ident GENERIC
makeoptions DEBUG=-g # Build kernel with gdb(1) debug symbols
options SCHED_4BSD # Classic BSD scheduler
#options SCHED_ULE # ULE scheduler
options PREEMPTION # Enable kernel thread preemption
options INET # InterNETworking
options FFS # Berkeley Fast Filesystem
options SOFTUPDATES # Enable FFS soft updates support
options UFS_ACL # Support for access control lists
options UFS_DIRHASH # Improve performance on big directories
options UFS_GJOURNAL # Enable gjournal-based UFS journaling
options MD_ROOT # MD is a potential root device
options NFSCLIENT # Network Filesystem Client
options NFSSERVER # Network Filesystem Server
options NFSLOCKD # Network Lock Manager
options NFS_ROOT # NFS usable as /, requires NFSCLIENT
options MSDOSFS # MSDOS Filesystem
options CD9660 # ISO 9660 Filesystem
options PROCFS # Process filesystem (requires PSEUDOFS)
options PSEUDOFS # Pseudo-filesystem framework
options GEOM_PART_GPT # GUID Partition Tables.
options GEOM_LABEL # Provides labelization
options COMPAT_43TTY # BSD 4.3 TTY compat (sgtty)
options SCSI_DELAY=5000 # Delay (in ms) before probing SCSI
options KTRACE # ktrace(1) support
options STACK # stack(9) support
options SYSVSHM # SYSV-style shared memory
options SYSVMSG # SYSV-style message queues
options SYSVSEM # SYSV-style semaphores
options P1003_1B_SEMAPHORES # POSIX-style semaphores
options _KPOSIX_PRIORITY_SCHEDULING # POSIX P1003_1B real-time extensions
options PRINTF_BUFR_SIZE=128 # Prevent printf output being interspersed.
options KBD_INSTALL_CDEV # install a CDEV entry in /dev
options HWPMC_HOOKS # Necessary kernel hooks for hwpmc(4)
options AUDIT # Security event auditing
options MAC # TrustedBSD MAC Framework
options FLOWTABLE # per-cpu routing cache
#options KDTRACE_FRAME # Ensure frames are compiled in
#options KDTRACE_HOOKS # Kernel DTrace hooks
options INCLUDE_CONFIG_FILE # Include this file in kernel
# Make an SMP-capable kernel by default
options SMP # Symmetric MultiProcessor Kernel
# Debugging options
options BREAK_TO_DEBUGGER # Sending a serial BREAK drops to DDB
options ALT_BREAK_TO_DEBUGGER # Permit <CR>~<Ctrl-b> to drop to DDB
options KDB # Enable kernel debugger support
options KDB_TRACE # Print stack trace automatically on panic
options DDB # Support DDB
options DDB_NUMSYM # Print numeric value of symbols
options GDB # Support remote GDB
# CPU frequency control
device cpufreq
# Bus support.
device acpi
device pci
# Floppy drives
device fdc
# ATA and ATAPI devices
# NOTE: "device ata" is missing because we use the Modular ATA core
# to only include the ATA-related drivers we need (e.g. AHCI).
device atadisk # ATA disk drives
device ataraid # ATA RAID drives
device atapicd # ATAPI CDROM drives
options ATA_STATIC_ID # Static device numbering
# Modular ATA
device atacore # Core ATA functionality
device ataisa # ISA bus support
device atapci # PCI bus support; only generic chipset support
device ataahci # AHCI SATA
device ataintel # Intel
# SCSI peripherals
device scbus # SCSI bus (required for SCSI)
device da # Direct Access (disks)
device cd # CD
device pass # Passthrough device (direct SCSI access)
device ses # SCSI Environmental Services (and SAF-TE)
options CAMDEBUG # CAM debugging (camcontrol debug)
# atkbdc0 controls both the keyboard and the PS/2 mouse
device atkbdc # AT keyboard controller
device atkbd # AT keyboard
device psm # PS/2 mouse
device kbdmux # keyboard multiplexer
device vga # VGA video card driver
device splash # Splash screen and screen saver support
# syscons is the default console driver, resembling an SCO console
device sc
device agp # support several AGP chipsets
# Serial (COM) ports
device uart # Generic UART driver
# PCI Ethernet NICs.
device em # Intel PRO/1000 Gigabit Ethernet Family
# Wireless NIC cards
device wlan # 802.11 support
options IEEE80211_DEBUG # enable debug msgs
options IEEE80211_AMPDU_AGE # age frames in AMPDU reorder q's
device wlan_wep # 802.11 WEP support
device wlan_ccmp # 802.11 CCMP support
device wlan_tkip # 802.11 TKIP support
device wlan_amrr # AMRR transmit rate control algorithm
device wlan_acl # MAC Access Control List support
# Pseudo devices.
device loop # Network loopback
device random # Entropy device
device ether # Ethernet support
device pty # BSD-style compatibility pseudo ttys
device md # Memory "disks"
device gif # IPv6 and IPv4 tunneling
device faith # IPv6-to-IPv4 relaying (translation)
device firmware # firmware assist module
# The `bpf' device enables the Berkeley Packet Filter.
# Be aware of the administrative consequences of enabling this!
# Note that 'bpf' is required for DHCP.
device bpf # Berkeley packet filter
# USB support
device uhci # UHCI PCI->USB interface
device ohci # OHCI PCI->USB interface
device ehci # EHCI PCI->USB interface (USB 2.0)
device usb # USB Bus (required)
#device udbp # USB Double Bulk Pipe devices
device uhid # "Human Interface Devices"
device ukbd # Keyboard
device umass # Disks/Mass storage - Requires scbus and da
device ums # Mouse
# Intel Core/Core2Duo CPU temperature monitoring driver
device coretemp
# SMBus support, needed for bsdhwmon
device smbus
device smb
device ichsmb
# Intel ICH hardware watchdog support
device ichwd
# pf ALTQ support
options ALTQ
options ALTQ_CBQ # Class Bases Queueing
options ALTQ_RED # Random Early Detection
options ALTQ_RIO # RED In/Out
options ALTQ_HFSC # Hierarchical Packet Scheduler
options ALTQ_CDNR # Traffic conditioner
options ALTQ_PRIQ # Priority Queueing
options ALTQ_NOPCC # Required for SMP build